 |
Главная |


Умножение матрицы на вектор при разделении данных по столбцам.
|
из
5.00
|
Параллельные методы умножения матрицы на вектор
( лаба №1 )
| Выполнили студенты 1 курса магистратуры, | |
| группы ПМИ | |
| механико-математического факультета | |
| Габдуллин Артём _______________ | |
| Моисеенков Максим_____________ Нурбакова Диана _______________ |
| Принял: | |
| доцент кафедры прикладной | |
| математики и информатики ПГУ, | |
| к.ф.-м.н., доц. | |
| Деменев А.Г.____________________________ |
Пермь 2010
Цель лабораторной работы.
Реализация последовательного и параллельных алгоритмов умножения матрицы на вектор при использовании 2-х ядерной вычислительной системы с общей памятью.
Постановка задачи.
В результате умножения матрицы  и вектора
и вектора  , получается вектор
, получается вектор  , каждый i-ый элемент которого есть результат скалярного умножения i-й строки матрицы
, каждый i-ый элемент которого есть результат скалярного умножения i-й строки матрицы  (обозначим эту строчку
(обозначим эту строчку  ) и вектора
) и вектора  .
.

Тем самым получение результирующего вектора 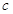 предполагает повторение
предполагает повторение  однотипных операций по умножению строк матрицы и вектора . Каждая такая операция включает умножение элементов строки матрицы и вектора (
однотипных операций по умножению строк матрицы и вектора . Каждая такая операция включает умножение элементов строки матрицы и вектора (  операций) и последующее суммирование полученных произведений (
операций) и последующее суммирование полученных произведений (  операций).
операций).
Общее количество необходимых скалярных операций есть величина 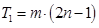 .
.
1. Поcледовательный алгоритм умножения матрицы на вектор
void SerialResultCalculation(double* pMatrix, double* pVector,
double* pResult, int Size) {
int i, j; // Loop variables
for (i=0; i<Size; i++) {
pResult[i]=0;
for (j=0; j<Size; j++)
pResult[i] += pMatrix[i*Size+j]*pVector[j];
}
}
Умножение матрицы на вектор при разделении данных по строкам.
Базовая подзадача - скалярное умножение одной строки матрицы на вектор. После завершения вычислений каждая базовая подзадача определяет один из элементов вектора результата c.
В общем виде схема информационного взаимодействия подзадач в ходе выполняемых вычислений показана на рис.1. Количество вычислительных операций для получения скалярного произведения одинаково для всех базовых подзадач.
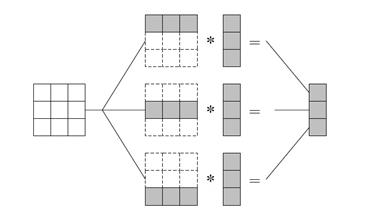
Рисунок 1 . Организация вычислений при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на разделении матрицы по строкам.
Каждый поток параллельной программы использует только «свои» данные, ему не требуются данные, которые в данный момент обрабатывает другой поток, нет обмена данными между потоками, не возникает необходимости синхронизации. Т.е. практически нет накладных расходов на организацию параллелизма (за исключением расходов на организацию и закрытие параллельной секции), и можно ожидать линейного ускорения. Однако, как будет видно из представленных результатов, ускорение далеко от линейного.
Время решения задачи одним потоком складывается из времени, когда процессор непосредственно выполняет вычисления, и времени, которое тратится на чтение необходимых для вычислений данных из ОП в кэш. При этом время, необходимое на чтение данных, может в несколько раз превосходить время счета.
Процесс выполнения последовательного алгоритма умножения матрицы на вектор может быть представлен диаграммой, изображенной на рис.2.

Рисунок 2. Диаграмма состояний процесса выполнения последовательного алгоритма
умножения матрицы на вектор.
Время выполнения последовательного алгоритма складывается из времени вычислений и времени доступа к памяти: 
 , где
, где  - это количество выполненных операций,
- это количество выполненных операций, 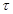 - время выполнения одной операции, - размерность матрицы.
- время выполнения одной операции, - размерность матрицы.
 , где
, где  - объем данных, которые необходимо закачать в кэш процессора,
- объем данных, которые необходимо закачать в кэш процессора,  - скорость доступа (пропускная способность канала доступа) ОП.
- скорость доступа (пропускная способность канала доступа) ОП.
Таким образом,  .
.
Для оценки , измерим время выполнения последовательного алгоритма при
 , т.к. матрица и вектор полностью поместятся в кэш ВЭ. (У нас размер кэш равен 2048 кбайт, поэтому
, т.к. матрица и вектор полностью поместятся в кэш ВЭ. (У нас размер кэш равен 2048 кбайт, поэтому  ). Чтобы исключить необходимость выборки данных из ОП, перед началом вычислений заполним матрицу и вектор случайными числами – выполнение этого действия гарантирует закачку данных в кэш. Далее при решении задачи все время будет тратиться на вычисления, так как нет необходимости загружать данные из ОП.
). Чтобы исключить необходимость выборки данных из ОП, перед началом вычислений заполним матрицу и вектор случайными числами – выполнение этого действия гарантирует закачку данных в кэш. Далее при решении задачи все время будет тратиться на вычисления, так как нет необходимости загружать данные из ОП.
Получим 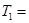 0,00000308.
0,00000308.
Тогда 
Теперь, оценим при  :
:  8 121 537 238,29
8 121 537 238,29
В таблице 1 и на рис.3 представлено сравнение реального времени последовательного алгоритма умножения матрицы на вектор и теоретического.
Таблица 1. Сравнение экспериментального и теоретического времени выполнения последовательного
алгоритма умножения матрицы на вектор.


Рисунок 3. График зависимости экспериментального и теоретического времени выполнения последовательного алгоритма от объема исходных данных (ленточное разбиение матрицы по строкам
В многоядерных процессорах Intel архитектуры Core 2 Duo ядра процессоров разделяют общий канал доступа к памяти. Т.е., несмотря на то, что вычисления могут выполняться ядрами параллельно, доступ к памяти осуществляется строго последовательно. Следовательно, время  выполнения параллельного алгоритма в системе с
выполнения параллельного алгоритма в системе с 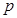 вычислительными элементами, с использованием потоков и при описанной выше схеме доступа к памяти может быть оценено при помощи следующего соотношения:
вычислительными элементами, с использованием потоков и при описанной выше схеме доступа к памяти может быть оценено при помощи следующего соотношения:  .
.
void ParallelResultCalculation_rows (double* pMatrix, double* pVector,
double* pResult, int Size) {
int i, j; // Loop variables
#pragma omp parallel private (i,j)
#pragma omp for
for (i=0; i<Size; i++) {
for (j=0; j<Size; j++)
pResult[i] += pMatrix[i*Size+j]*pVector[j];
}
}
Результаты вычислительных экспериментов приведены в таблице 2. Времена выполнения алгоритмов указаны в секундах.
Ускорение есть результат деления времени работы последовательного алгоритма на время работы параллельного.
Таблица 2. Результаты вычислительных экспериментов для параллельного алгоритма умножения
матрицы на вектор при ленточной схеме разделении данных по строкам.

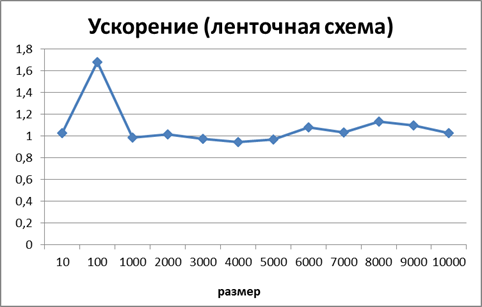
Рисунок 4. Зависимость ускорения от количества исходных данных при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на ленточном горизонтальном разбиении матрицы

Рисунок 5. График зависимости экспериментального и теоретического времени выполнения параллельного алгоритма от объема исходных данных при использовании двух потоков (ленточное разбиение матрицы по строкам)
ВЫВОД:
Замедление работы программы при использовании параллельного алгоритма (библиотека OpenMP) можно объяснить следующим отчётом профилировщика (см. Рисунок 6).

Рисунок 6. Сравнение данных профилировщика последовательной и параллельной программ
Как видно, значительное время при выполнении программы затрачивается в библиотеке libiomp 5 md . dll.
Умножение матрицы на вектор при разделении данных по столбцам.
Базовая подзадача - операция умножения столбца матрицы  на один из элементов вектора
на один из элементов вектора  . Для организации вычислений в этом случае каждая базовая подзадача
. Для организации вычислений в этом случае каждая базовая подзадача  , должна иметь доступ к i-у столбцу матрицы .
, должна иметь доступ к i-у столбцу матрицы .
Каждая базовая задача  выполняет умножение своего столбца матрицы
выполняет умножение своего столбца матрицы  на элемент
на элемент  , в итоге в каждой подзадаче получается вектор
, в итоге в каждой подзадаче получается вектор 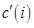 промежуточных результатов. Для получения элементов результирующего вектора с необходимо просуммировать вектора
промежуточных результатов. Для получения элементов результирующего вектора с необходимо просуммировать вектора  , которые были получены каждой подзадачей.
, которые были получены каждой подзадачей.

Рисунок 7. Организация вычислений при выполнении параллельного алгоритма умножения матрицы на вектор с использованием разбиения матрицы по столбцам.
При выполнении параллельного алгоритма умножения матрицы на вектор, основанного на вертикальном разделении матрицы, выполняется больше арифметических операций, т.к. на каждой итерации внешнего цикла после вычисления каждым потоком своей частичной суммы необходимо выполнить редукцию полученных результатов. Сложность выполнения операции редукции –  . После выполнения редукции данных, необходимо запомнить результат в очередной элемент результирующего вектора. Таким образом, время вычислений для данного алгоритма определяется формулой:
. После выполнения редукции данных, необходимо запомнить результат в очередной элемент результирующего вектора. Таким образом, время вычислений для данного алгоритма определяется формулой:  .
.
На выполнение подкачек данных в кэш тоже тратится некоторое время. Пусть  - накладные расходы на организацию параллельности на каждой итерации. Тогда суммарные накладные расходы составляют:
- накладные расходы на организацию параллельности на каждой итерации. Тогда суммарные накладные расходы составляют: 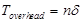 .
.
Таким образом, время выполнения параллельного алгоритма умножения матрицы на вектор, основанного на вертикальном разделении матрицы, может быть вычислено по формуле:
 .
.
void ParallelResultCalculation_columns(double* pMatrix, double* pVector, double* pResult, int Size) {
int i, j; // Loop variables
double IterGlobalSum = 0;
for (i=0; i<Size; i++) {
IterGlobalSum = 0;
#pragma omp parallel for reduction(+:IterGlobalSum)
for (j=0; j<Size; j++)
IterGlobalSum += pMatrix[i*Size+j]*pVector[j];
pResult[i] = IterGlobalSum;
}
}
Результаты вычислительных экспериментов приведены в таблице.
Таблица 3. Результаты вычислительных экспериментов для параллельного алгоритма умножения
матрицы на вектор при ленточной схеме разделении данных по столбцам.


Рисунок 8. Зависимость ускорения от количества исходных данных при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на ленточном вертикальном разбиении матрицы
Для нахождения  воспользуемся методом наименьших квадратов. Будем минимизировать квадрат разницы между экспериментальными и теоретическими значениями времени, при этом будет выступать в качестве подгоночного параметра. Воспользуемся функцией поиска решений в Excel.
воспользуемся методом наименьших квадратов. Будем минимизировать квадрат разницы между экспериментальными и теоретическими значениями времени, при этом будет выступать в качестве подгоночного параметра. Воспользуемся функцией поиска решений в Excel.
Будем минимизировать величину 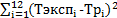
Таким образом, получаем = 5,27565E-06 с=5,3 мкс

Рисунок 9. График зависимости экспериментального и теоретического времени выполнения параллельного алгоритма от объёма исходных данных при использовании двух потоков (ленточное разбиение матрицы по столбцам)
|
из
5.00
|
Обсуждение в статье: Умножение матрицы на вектор при разделении данных по столбцам. |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы