 |
Главная |


Теорема о минимальной средней длине кодового слова
|
из
5.00
|
Рассмотрим теперь случай кодирования не отдельных букв источника, а последовательностей из L букв.
Теорема 4.
Формулировка. Для данного дискретного источника без памяти (с независимыми буквами) и энтропией H и объемом вторичного алфавита m при кодировании блоками по L букв существует префиксный код со средней длиной кодового слова, отвечающей неравенству:
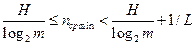 .
.
Доказательство.
Последовательность из L букв можно рассматривать как новую супербукву. Тогда можно использовать теорему 3, согласно которой минимальная средняя длина кодового слова для такого сообщения ограничивается неравенством:
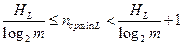 .
.
Так как отдельные буквы предполагаются независимыми, то энтропия последовательности L букв 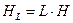 . Кроме того, средняя длина кода для последовательности L букв
. Кроме того, средняя длина кода для последовательности L букв 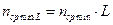 , тогда
, тогда
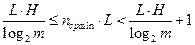 .
.
После деления всех частей неравенства на L получаем окончательный результат: .
Из теоремы 4 следует, что если кодировать блоками, то, увеличивая размер блоков L, можно сколь угодно приблизиться к нижней границе средней длины кодового слова, т.е. 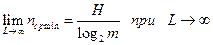 .
.
Назначение и порядок построения оптимальных кодов Шеннона-Фэно и Хаффмена.
Коды Хаффмена
На этом алгоритме построена процедура построения оптимального кода, предложенная в 1952 году Хаффменом:
1) буквы первичного алфавита выписываются в основной столбец в порядке убывания вероятностей;
2) две последние буквы объединяются в одну вспомогательную букву, которой приписывается суммарная вероятность;
3) вероятности букв, не участвовавших в объединении, и полученная суммарная вероятность снова располагаются в порядке убывания вероятностей в дополнительном столбце, а две последние объединяются;
4) процесс продолжается до тех пор, пока не получим единственную вспомогательную букву с вероятностью, равной единице.
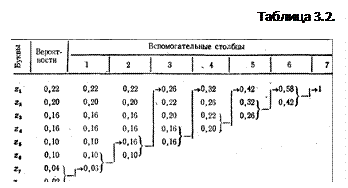 Методика поясняется примером, представленным табл. 3.2.
Методика поясняется примером, представленным табл. 3.2.
Для составления кодовой комбинации, соответствующей данному сообщению, необходимо проследить путь перехода вероятности сообщения по строкам и столбцам таблицы.
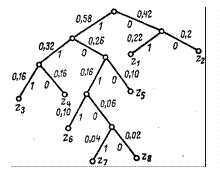 Для наглядности строится кодовое дерево. Из точки, соответствующей вероятности 1, направляются две ветви, причем ветви с большей вероятностью присваивается символ 1, а с меньшей − 0. Такое последовательное ветвление продолжаем до тех пор, пока не дойдем до каждой буквы. Кодовое дерево для алфавита букв, рассматриваемого в таблице, изображено на рис. 3.3.
Для наглядности строится кодовое дерево. Из точки, соответствующей вероятности 1, направляются две ветви, причем ветви с большей вероятностью присваивается символ 1, а с меньшей − 0. Такое последовательное ветвление продолжаем до тех пор, пока не дойдем до каждой буквы. Кодовое дерево для алфавита букв, рассматриваемого в таблице, изображено на рис. 3.3.
Теперь, двигаясь по кодовому дереву сверху вниз, можно записать для каждой буквы соответствующую ей кодовую комбинацию (табл. 3.3).
Таблица 3.3
| Z1 | Z2 | Z3 | Z4 | Z5 | Z6 | Z7 | Z8 |
Коды Шеннона−Фэно:
Ранее, независимо друг от друга Шенноном и Фэно была предложена другая процедура построения эффективного кода. Получаемый при ее помощи код называют кодом Шеннона−Фэно.
Код Шеннона−Фэно строится следующим образом:
1) буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей;
2) затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы;
3) всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним 0;
4) каждая из полученных групп, в свою очередь, разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. ;
|
из
5.00
|
Обсуждение в статье: Теорема о минимальной средней длине кодового слова |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы